
早稲田大学修士1年のRAの真殿です。
AAAI WSでの発表のため会議に参加したので、レポートをまとめたいと思います
はじめに
今回,アメリカのニューヨーク州ニューヨークで開催されましたAAAI 2020のAIoT WorkShopにおいて口頭発表を行いました.AAAIの概要と様子をお伝えしたいと思います.
AAAIとは
Association for the Advancement of Artificial Intelligence の略称であり,人工知能トップの国際会議です.会議はTutorial・口頭発表・口頭発表者によるポスター展示・WorkShop・Invited Talkによって構成されています.企業の出資も同時にありました。中国人がコロナウイルスのために欠席していましたが、それでも会場のHilton Hotelに十分に混雑させるほどの人がいました。
今回のAAAIの論文採択数は1591本であり、採択率は20.56%でした. そのうちspotlightを含まないoralは454本で、比較的口頭発表の機会は多い印象があります.
参加した感じだと、直近のTop Conference(Neurips, ECCV, etc.)に落ちたものも多くあり、AAAIを直接狙う人がそれほど多いかというとそういうわけではなさそうという印象がありました.
また、投稿数はMachine Learning, CV, NLP などのホットのTopicは投稿数が1000を超えていて、反対にGame Theoryなどのニッチな分野は100に達していなく、分野毎に採択の難しさも異なっていると感じています.

学会の開催場所と雰囲気
今回のAAAIの開催地はアメリカ,ニューヨークのHilton Hotelです.都心なので、周りはビルだらけですが、美術館や自由の女神、タイムズスクエアなどの有名観光地もここNYに位置しています。同じ日本人の参加者は八村塁のバスケの試合を見に行ったりなどもしていたそうです.(自分は観光をし忘れていました)
アメリカの主食はピザらしいですが、ハンバーガーとクッキーを食べつつ、ずっとコーヒーを飲んでいました。食事は日本の方が健康にいいと思いますが、ジャンクフードも悪くありませんでした。Hilton Hotelの近くにいくつかカフェがあるのですが、カフェで売っている野菜スープを飲むととてもおいしさを感じました
AIoT WorkShop
今回はAAAIの中でもAIoTのワークショップに参加しました.
今回の本Workshopへの投稿数は27件で、うち14件が採択されていました.
我々の発表
今回は画像認識における秘匿技術を用いた上で、高精度な識別精度を満たすようなCloud Serviceの提案を論文として、発表しました. 深層学習における、Privacyを保護した利用方法は近年特に研究されています(差分Privacy, 秘匿計算と深層学習など)。いずれの手法もPrivacyを保護可能ですが、今回は画像の見た目のみを保護するようなImage Scramblingという手法に注目しました。これらの画像はpixelをshuffleしただけなので、画像の情報がなくなっていることはありませんが、それを認識できるような仕組みはまだ進んでいません.
そのため、Image Scramblingされた画像を認識するAdaptation Networkを提案しました.
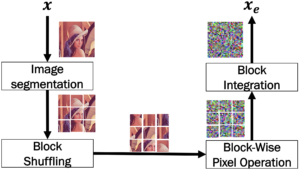
Image Scramblingは
- ブロックごとに分割
- ブロックの位置移動
- 各ブロック内のpixelをRandomにshuffle
する手法です.
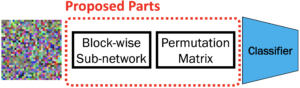
それを識別できるように、
- ブロックの位置移動を考慮したPermutation Matrix
- 各ブロック内の異なるpixel shuffleに対応した、Block-wise Sub-network
を組み込むことで識別を可能にしています、構造の詳細については割愛させて頂きます.
AAAIから感じたトレンド
気になった点(3点)は
- Graph & 強化学習の応用や研究の増加
- Complemantary Lebel LearningやContinual Learningなどのニッチなテーマでの発表がちらほら存在
- CV/ NLPはかなり細かいTaskを解いている
です。
-
Graph & 強化学習の応用や研究の増加
CV/NLP/MLの分野を中心に応用されている研究が多かったです、特に強化学習は各taskに置いて独自の環境(setting)から使いやすいのもあり、発表分件数が多い印象が受けられました. -
Complemantary Lebel LearningやContinual Learningなどのニッチなテーマでの発表がちらほら存在
Complemantary Lebel Learning : "絶対にこのLabelではない"という情報が与えられた上で、どうやって識別などのTaskを解くか?
Continual Learning : 過去に学習したTaskの情報を保持しながら、新たに学習するTaskの学習を行う手法
ですが、以上の話はまだまだ基礎的な話がなく、これからトレンドの一つになるのではないか?と感じています -
CV/ NLPはかなり細かいTaskを解いている
これらは応用研究もありましたが、どちらかというと"精度をどうしたら向上させられるか?"や"Attentionとどう向き合うか?"のような話が多い印象がありました.
気になった論文
差分プライバシー / 転移学習 / Image Edittingなどの分野は、自分の研究と関連していて興味がありました。その他、準同型暗号をモデルに組み込むなどの話もあり、興味を持ちました.
学会を通して感じた事・得た事
-
感じた事
Workshopの質は様々. M1~2で日本人で発表にきている人はほとんどいなかったので、これからはその少数に入れるように、いかにMain Conferenceに通るような研究(のための研究活動・生活)ができるかは重要だと思いました。まだまだ自分のネタで通す力が十分ついていないので、今年は自分のネタ・アイディアで推していきながら研究することを考えたいと思いました -
得た事
学会に参加する方の英語力がとても高いので、ほどほどの会話能力が必要。実際に会議に参加している人たちはとても優しい人が多いので、その代わりこちらから積極的に話しかけることが必要だということを改めて教えられました
来年度は産総研での研究で最低1~2本はMain Conferenceに投稿できるように進めていきたいと思います
